2025. 3. 25. 01:55ㆍ개발/👽 졸업 논문
생성 모델이란?
: 주어진 데이터를 학습하여 데이터 분포를 따르는 유사한 데이터를 생성하는 모델
생성 모델 vs 판별 모델
판별 모델
: 해당 이미지를 대표하는 특성들을 잘 찾는 것을 목표로 함
생성 모델
: 입력 이미지에 대한 데이터 분포를 학습하여 새로운 이미지를 생성하는 것을 목표로 함
생성 모델의 유형
생성 모델은 확률 변수를 구하느냐, 안 구하느냐에 따라 명시적 방법과 암시적 방법으로 나뉜다
명시적 방법은 확률 변수를 정의하여 사용하며, 대표적으로 변형 오토인코더가 있다
암시적 방법은 확률 변수에 대한 정의를 하지 않으며, 대표적으로 GAN이 있다
변형 오토인코더
오토인코더
: 입력을 출력으로 복사하는 신경망

위 그림과 같이 오토인코더는 인코더 > 은닉층(병목층) > 디코더 구조로 이루어져 있다
인코더 : 데이터를 입력받고, 특성에 대한 학습을 진행하며, 데이터의 차원을 축소시킴
은닉층 : 차원 축소된 데이터가 존재하는 부분
디코더 : 압축된 데이터를 원래대로 재구성하는 부분
인코더 -> 은닉층 -> 디코더 과정을 여러번 반복하며 손실 재구성을 진행한다
이때 손실 재구성이란 입력 데이터와 출력 데이터간의 오차를 줄여나가는 걸 의미한다
오토인코더에서 가장 주목해야 하는 부분은 데이터 압축인데,
데이터를 압축함으로써 메모리 측면에서 비용을 아낄 수 있고
특성의 개수를 줄여줘 차원의 저주를 예방할 수 있다
변형 오토인코더
변형 오토인코더는 오토인코더로부터 파생된 개념이다
따라서 기본적인 인코더 > 은닉층 > 디코더 구조는 그대로 가져간다
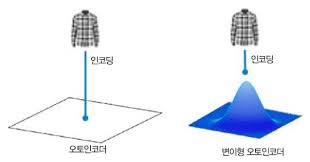
위 그림과 같이 일반적인 오토인코더와 변형 오토인코더의 차이점은
일반적인 오토인코더는 데이터를 특정한 벡터값으로 압축하지만,
변형 오토인코더는 데이터를 확률 분포로 압축한다는 것이다
특정값이 아닌 범위로 데이터를 압축함으로써 데이터 간 연속성을 확보하고, 생성에서의 자율성을 확보하게 된다
( 특정 벡터값으로 압축하게 되면 데이터가 불연속해 생성한 데이터가 부자연스러울 가능성이 높음 )
( 디코더가 특정 벡터값을 그대로 복원하는 것이 아니라 어떠한 범위 내에서 데이터를 샘플링해 복원하게 되면 생성 결과가 좀 더 다양해짐 )
변형 오토인코더에서의 손실 재구성은
1. 입력 데이터와 출력 데이터 간의 오차를 줄여나가는 방식
2. 데이터 압축 과정에서 생성된 확률 분포가 정규 분포를 따르도록 강제하는 방식 (KL 발산)
으로 두가지가 있다
1번은 앞서 일반적인 오토인코더와 같은 개념이다
변형 오토인코더에서 인코더는 입력된 데이터 포인트들마다 각각의 확률 분포를 부여하는데
이때 만약 데이터 포인트들마다 분포가 제각각이라면 데이터 샘플링이 알맞게 이루어지지 않을 것이다
따라서 KL 발산을 통해 각 데이터 포인트들의 확률 분포를 일반화해주는 것이다
GAN ( Generative Adverserial Networks )
: 적대적 생성 신경망
GAN의 생성 모델과 판별 모델

GAN은 생성자와 판별자로 구성되어 있다
생성자와 판별자의 관계는 주로 위조 지폐범과 경찰로 비유하는데,
경찰(판별자)은 지폐의 진짜 / 가짜 여부를 더 잘 판별하는 방향으로
위조범(생성자)은 경찰(판별자)이 위조 지폐를 진짜로 판별하도록 속이는 방향으로
경쟁하며 점차 발전한다
판별자
: 판별자에 진짜 이미지 데이터를 입력시킨 뒤, 이를 '진짜'로 판별하도록 학습시킨다
: 판별자에 생성자가 만들어낸 가짜 이미지 데이터를 입력시킨 뒤, 이를 '가짜'로 판별하도록 학습시킨다
생성자
: 생성자는 판별자가 생성된 가짜 이미지를 '진짜'라고 판별하도록 발전한다
앞서 말했던 변형 오토인코더와 달리,
GAN의 생성자에는 입력 데이터가 존재하지 않으며,
따라서 입력 데이터로부터 압축한 확률 분포 또한 존재하지 않는다
그렇다면 생성자는 어떻게 가짜 이미지를 생성하느냐 하면...
노이즈 벡터 z로부터 데이터를 랜덤하게 샘플링해서 생성하게 된다
그리고 여러번의 반복을 통해 점차 판별자가 가짜 이미지를 구분하지 못하는 방향으로 노이즈 벡터 z를 변형해나간다
GAN의 손실 재구성
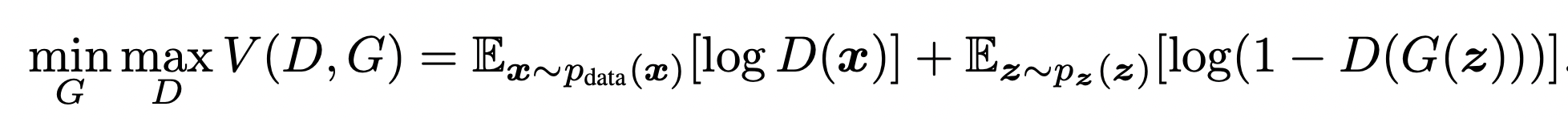
D(x) : 판별자가 진짜 이미지를 '진짜'로 판별 ( 1에 가까울수록 잘 판별함 )
G(z) : 랜덤 노이즈 벡터 z로부터 생성자가 만들어낸 '가짜' 이미지
D(G(z)) : 가짜 이미지를 '가짜'로 판별한 확률 ( 0에 가까울수록 잘 판별함 )
따라서 판별자는 위 값이 클수록, 생성자는 위 값이 작을수록 더 잘 발달한 것이다