2023. 11. 22. 00:07ㆍ개발/💠 Alchemist
1. 과제 - 교재 회귀 모델 실습 예제 필사
< 캐글 자전거 대여 수요 예측 실습 >
https://sosoeunii.tistory.com/113
💠 회귀 - 캐글 자전거 대여 수요 예측 실습 💠
< 캐글 자전거 대여 수요 예측 > https://www.kaggle.com/c/bike-sharing-demand Bike Sharing Demand | Kaggle www.kaggle.com 1. 데이터 세트 로딩 및 데이터 전처리, 모델 import 데이터 세트, 모델 import import numpy as np import p
sosoeunii.tistory.com
< 캐글 주택 가격: 고급 회귀 기법 >
https://sosoeunii.tistory.com/114
💠 회귀 - 캐글 주택 가격: 고급 회귀 기법 💠
< 캐글 주택 가격: 고급 회귀 기법 > https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/overview House Prices - Advanced Regression Techniques | Kaggle www.kaggle.com 1. 데이터 세트 로딩 및 데이터 전처리
sosoeunii.tistory.com
2. 추가 실습
<Medical Cost Personal>

https://www.kaggle.com/datasets/mirichoi0218/insurance
Medical Cost Personal Datasets
Insurance Forecast by using Linear Regression
www.kaggle.com
1. 데이터세트 로딩, 모델 import
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn.preprocessing import (OneHotEncoder, LabelEncoder, StandardScaler,
MinMaxScaler, PowerTransformer, QuantileTransformer)
from sklearn.model_selection import KFold, StratifiedKFold, train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
from sklearn.linear_model import LinearRegression, ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
%matplotlib inline
warnings.filterwarnings(action = 'ignore')
df = pd.read_csv('./insurance.csv', engine='python')
df.head()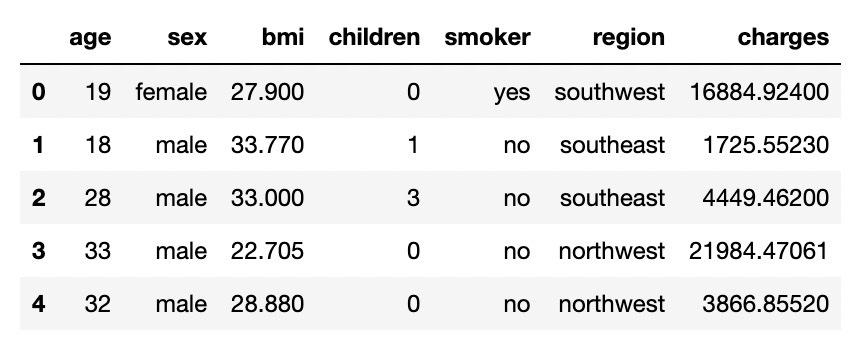
2. 데이터 전처리
데이터세트 정보 확인
# 결측치 여부와 데이터의 자료형 확인
df.info()
- 데이터 타입 : 숫자형, 문자형 존재
- Null 값 없음
# 데이터의 평균과 표준편차, 최댓값, 최솟값, 사분위수 확인
df.describe()
데이터 시각화
# 히스토그램을 통해 각 변수들의 분포 나타냄
fig, ax = plt.subplots(2, 3, figsize=(30,20))
idx = 0 # 보험료를 제외한 feature들을 지정할 인덱스
for i in range(2):
for j in range(3):
colname = list(df.columns)[idx]
ax[i][j].hist(df[colname], bins = 20)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Frequency')
idx += 1
필요 없는 칼럼 삭제
temp = df.drop(['sex', 'smoker', 'region'], axis=1)
temp.corr()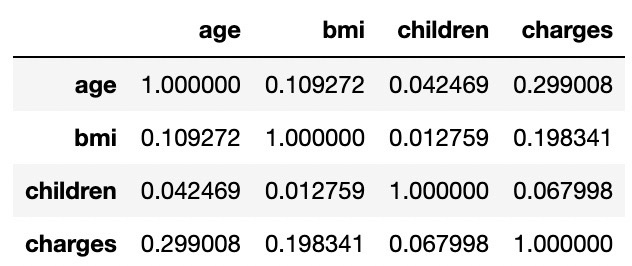
칼럼별 정보 시각화
pd.plotting.scatter_matrix(df, figsize=(16,16))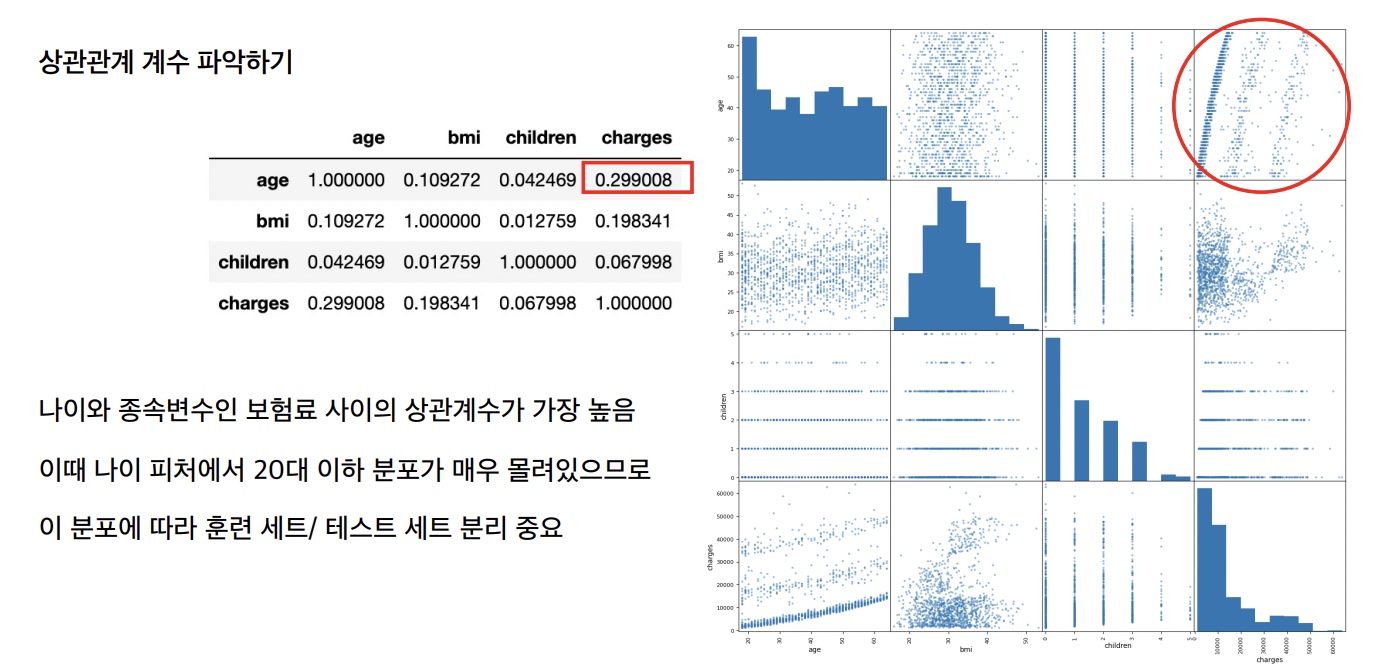
'Age' 칼럼 정보 확인
print(df['age'].min())
print(df['age'].max())
'Age' 구간 설정
# 연령별 구간 설정
bins = [0, 20, 25, 30, 35, 40, 45, 50, 55, 60, np.inf]
age_bin = pd.cut(df['age'], bins=bins, labels=[i+1 for i in range(len(bins)-1)])
#len(bins)
#age_bin
df['age_bin'] = age_bin
df.head()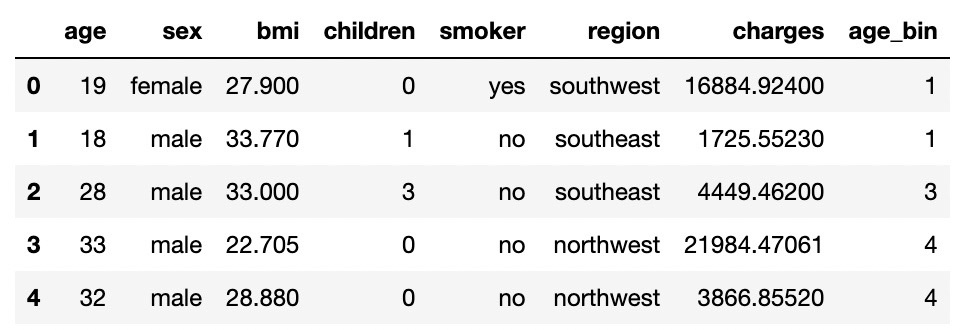
이상치 탐지를 위한 시각화 - boxplot 이용
# 이상치 탐지를 위해 boxplot 그리기
plt.subplot(1,3,1)
sns.boxplot(data=df, y='age')
plt.subplot(1,3,2)
sns.boxplot(data=df, y='children')
plt.subplot(1,3,3)
sns.boxplot(data=df, y='bmi')
- boxplot을 통해 'bmi' 칼럼에 이상치로 추정되는 값이 있음을 확인할 수 있다
'bmi' 칼럼의 이상치 파악 - IQR 이용
# IQR(Q3-Q1)로부터 이상치 파악하기
bmi_q1 = df['bmi'].quantile(q=0.25)
bmi_q3 = df['bmi'].quantile(q=0.75)
iqr = bmi_q3 - bmi_q1
# (q1-(iqr*1.5))와 (q3_(iqr*1.5))를 벗어난 값이 이상치
condi1 = (df['bmi'] < (bmi_q1 - (1.5 * iqr)))
condi2 = (df['bmi'] > (bmi_q3 + (1.5 * iqr)))
outliers = df[condi1 | condi2]
outliers['bmi']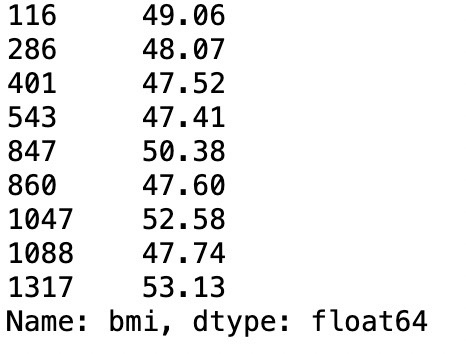
outliers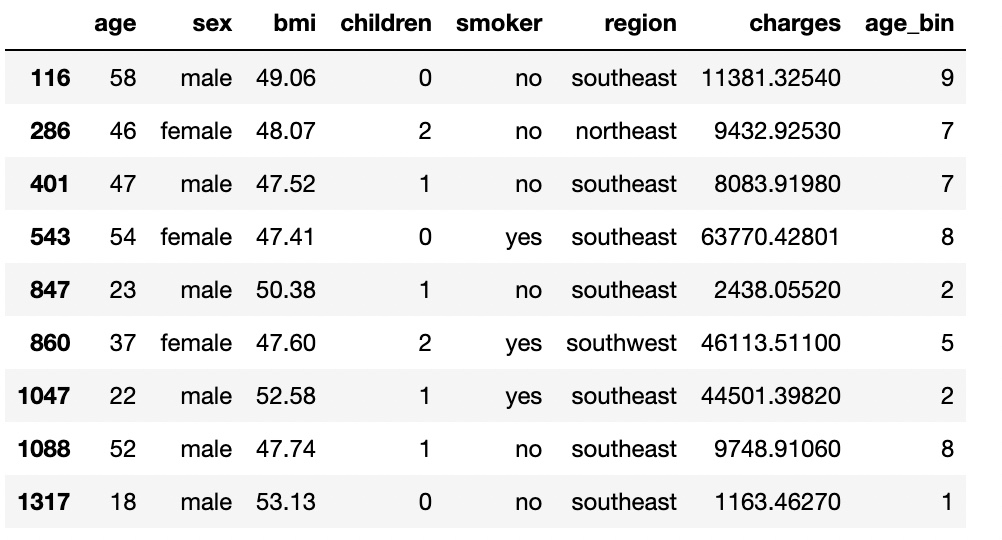
'bmi' 칼럼의 이상치 삭제
df.drop(outliers.index, axis=0, inplace=True)
df.info()
이상치 삭제 후 'bmi' 분포 확인
# bmi 분포 다시 그려보기
plt.figsize = (10, 10)
plt.hist(df['bmi'], bins=30)
plt.xlabel('bmi')
plt.ylabel('frequency')
plt.show()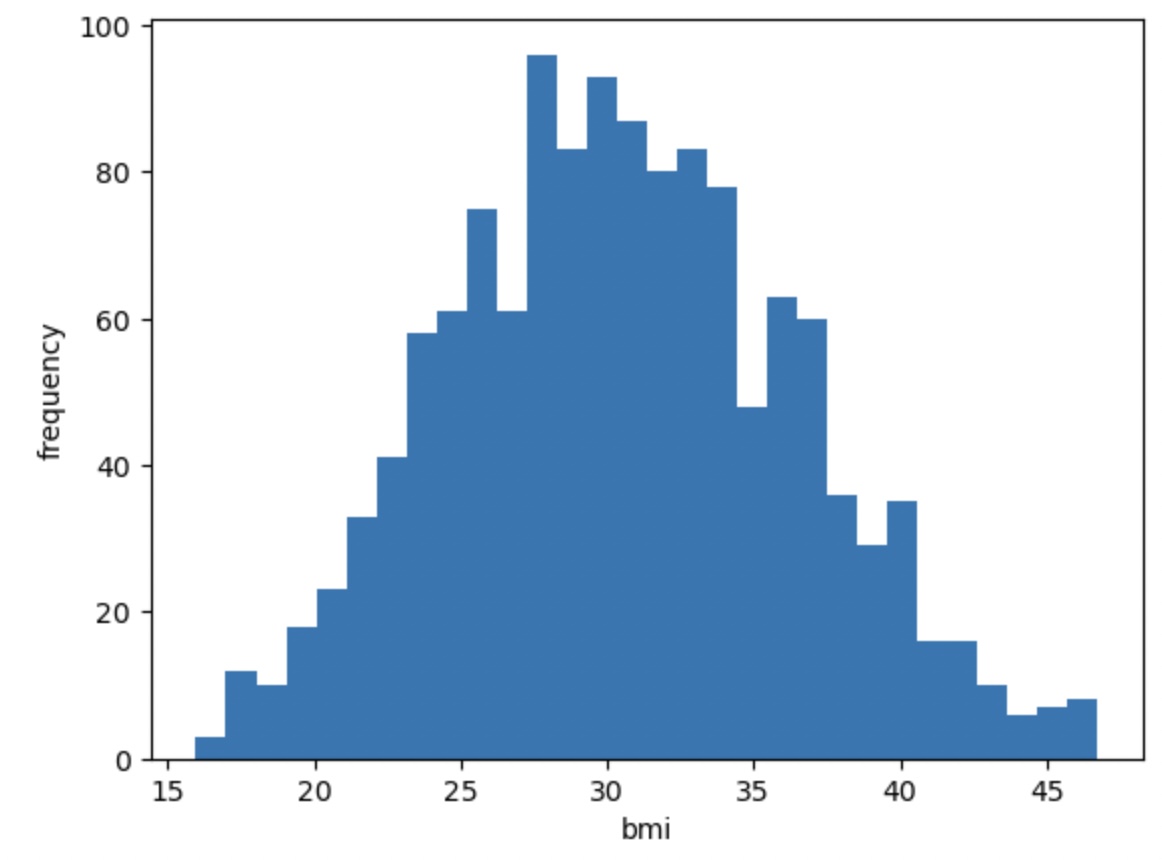
< Scaling, Transforming, Encoding >
Scaling
- Scaling을 진행할 때 항상 학습 세트에만 fitting을 하고 테스트 세트에는 fitting을 하면 안 됨
- Normalization
* 변수의 범위를 [0, 1] 사이로 옮기는 작업
* 사이킷런의 MinMaxScaler 사용
- Standardization
* 변수로부터 평균값을 빼고, 표준편차로 나누어 변수가 평균 0, 표준편차 1을 갖도록 맞춰주는 작업
* 사이킷런의 StandardScaler 사용
Normal Transformation
변수 정규 변환
1. Log Transformation (로그 변환)
2. Power Transformation
( 1 ) Box-Cox Transformation
( 2 ) Yeo-Johnson Transformation
( 3 ) Quantile Transformation
Normal Transformation
# 숫자형 변수에 대해 Box-Cox transformation, Quantile transformation, 로그 변환 진행
to_scale = ['age', 'bmi', 'children', 'charges']
df_to_scale = df[to_scale].copy()
quantile = QuantileTransformer(n_quantiles=100, random_state=42, output_distribution='normal')
power = PowerTransformer(method = 'yeo-johnson')
q_scaled = quantile.fit_transform(df_to_scale)
yj = power.fit_transform(df_to_scale)
q_scaled_df = pd.DataFrame(q_scaled, columns=to_scale)
scaled_df = pd.DataFrame(yj, columns=to_scale)
logged_df = pd.DataFrame(np.log1p(df_to_scale), columns=to_scale)
fig, ax = plt.subplots(4, 4, figsize=(40,30))
for i in range(4):
idx = 0
for j in range(4):
colname = to_scale[idx]
if i == 0:
ax[i][j].hist(df_to_scale[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Frequency')
elif i == 1:
ax[i][j].hist(scaled_df[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Transformed Frequency')
elif i == 2:
ax[i][j].hist(q_scaled_df[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Transformed Frequency')
elif i == 3:
ax[i][j].hist(logged_df[colname], bins = 30)
ax[i][j].set_xlabel(colname)
ax[i][j].set_ylabel('Logged Frequency')
idx += 1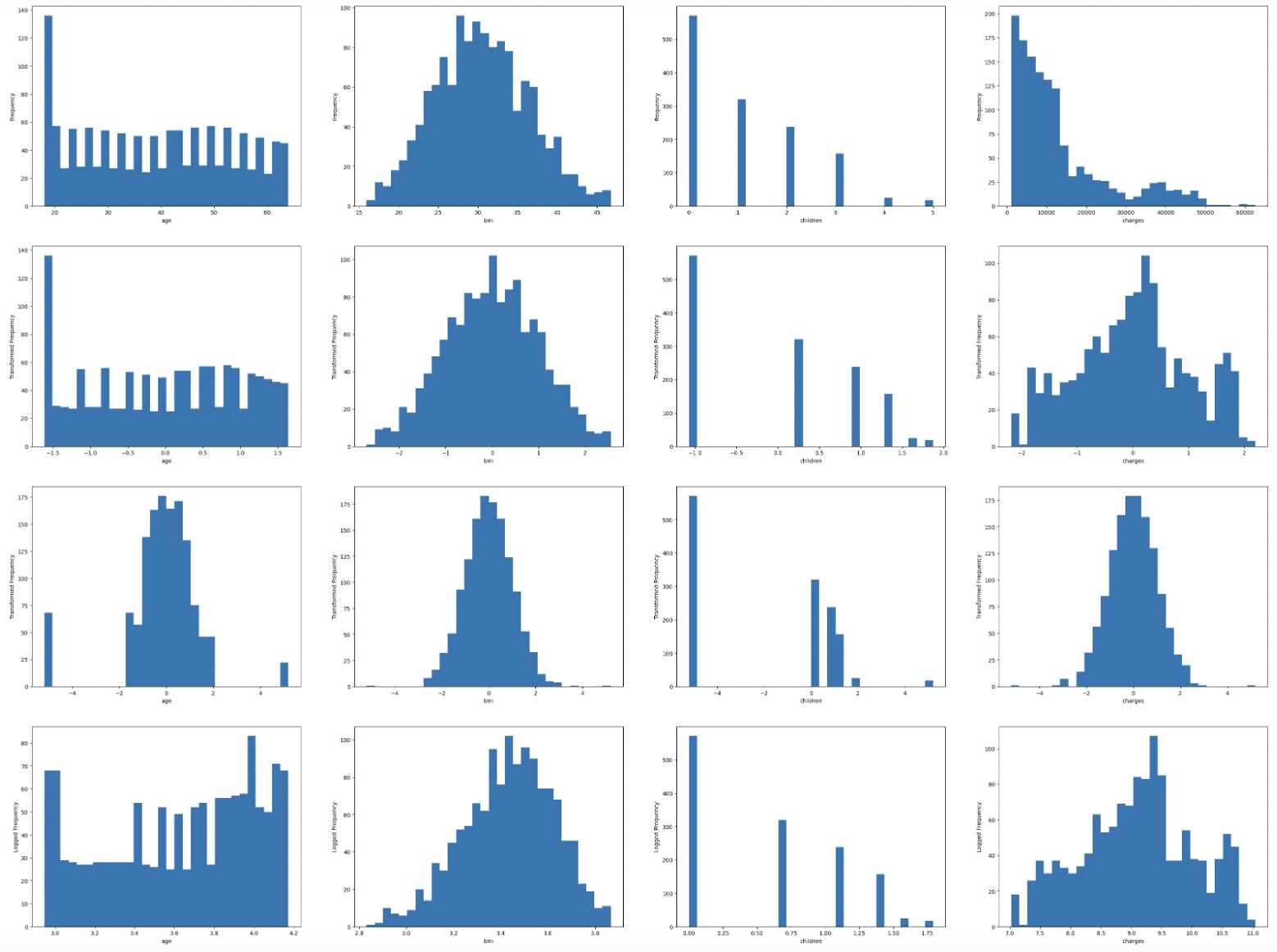
# training set와 test set 구분
X = df.drop(['charges'], axis = 1) # 'charges' 칼럼 삭제
y = df['charges'] # 'charges' 칼럼을 종속변수로 설정
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, shuffle = True, stratify = X['age_bin'])# Quantile Transformation
to_scale = ['age', 'bmi']
quantile = QuantileTransformer(n_quantiles = 10, random_state = 0, output_distribution='normal')
for col in to_scale:
quantile.fit(X_train[[col]])
X_train[col] = quantile.transform(X_train[[col]]).flatten()
X_test[col] = quantile.transform(X_test[[col]]).flatten()
Scaling
# 단위와 분포를 맞추기 위해 표준화 진행
cols = ['age', 'bmi', 'children']
for col in cols:
std = StandardScaler()
std.fit(X_train[[col]])
X_train[col] = std.transform(X_train[[col]]).flatten()
X_test[col] = std.transform(X_test[[col]]).flatten()
X_train.describe()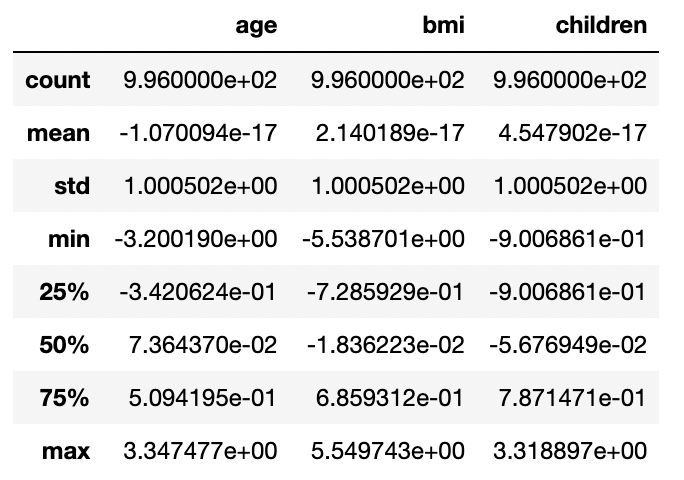
One-Hot Encoding
sex
# 원-핫 인코딩을 사용해 성별을 정수로 변환
encoder = OneHotEncoder()
sex_train = X_train[['sex']]
sex_test = X_test[['sex']]
encoder.fit(sex_train)
sex_train_onehot = encoder.transform(sex_train).toarray()
sex_test_onehot = encoder.fit_transform(sex_test).toarray()
# 여성을 0, 남성을 1로 두고 정수형으로 변환
X_train['sex'] = sex_train_onehot[:, 1].astype(np.uint8)
X_test['sex'] = sex_test_onehot[:, 1].astype(np.uint8)
smoker
# 원-핫 인코딩으로 흡연자 여부 변환
onehot_smoker = OneHotEncoder()
smoker_train = X_train[['smoker']]
smoker_test = X_test[['smoker']]
onehot_smoker.fit(smoker_train) # sklearn의 OneHotEncoder는 2차원 배열(또는 데이터프레임)이 input으로 들어가야 한다
smoker_train_onehot = onehot_smoker.transform(smoker_train).toarray()
smoker_test_onehot = onehot_smoker.transform(smoker_test).toarray()
X_train['smoker'] = smoker_train_onehot[:, 1].astype(np.uint8) # 비흡연자를 0, 흡연자를 1로
X_test['smoker'] = smoker_test_onehot[:, 1].astype(np.uint8)
region
# 거주 지역을 LabelEncoder로 숫자형으로 우선 변환
label_region = LabelEncoder()
label_region.fit(X_train['region']) # LabelEncoder 1차원 배열이 input으로 들어가야 한다
X_train['region'] = label_region.transform(X_train['region'])
X_test['region'] = label_region.transform(X_test['region'])# one-hot encoding으로 거주지역 바꾸기
onehot_region = OneHotEncoder()
region_train = X_train[['region']]
region_test = X_test[['region']]
onehot_region.fit(region_train)
region_train_onehot = onehot_region.transform(region_train).toarray()
region_test_onehot = onehot_region.transform(region_test).toarray()
X_train['region_1'] = region_train_onehot[:, 1].astype(np.uint8)
X_train['region_2'] = region_train_onehot[:, 2].astype(np.uint8)
X_train['region_3'] = region_train_onehot[:, 3].astype(np.uint8)
X_test['region_1'] = region_test_onehot[:, 1].astype(np.uint8)
X_test['region_2'] = region_test_onehot[:, 2].astype(np.uint8)
X_test['region_3'] = region_test_onehot[:, 3].astype(np.uint8)
X_train.drop(['region', 'age_bin'], axis=1, inplace=True)
X_test.drop(['region', 'age_bin'], axis=1, inplace=True)
3. 하이퍼 파라미터 튜닝 및 회귀 모델 학습 / 예측 / 평가
여러 회귀 모델의 default 객체 생성
# default 모델을 설정
lr = LinearRegression()
enet = ElasticNet(random_state=42)
dt = DecisionTreeRegressor(random_state=42)
rf = RandomForestRegressor(random_state=42)
ada = AdaBoostRegressor(random_state=42)
gbr = GradientBoostingRegressor(random_state=42)
xgb = XGBRegressor(random_state=42)
lgbm = LGBMRegressor(random_state=42)
models = [lr, enet, dt, rf, ada, gbr, xgb, lgbm]
GBM - 하이퍼 파라미터 튜닝 (GridSearchCV 이용)
# GBM
gbr_params = {
'learning_rate': [0.01, 0.05, 0.1],
'n_estimators': [50, 80, 100, 200, 300],
'max_depth': [3, 5, 7, 9],
'min_samples_split': [2, 3, 4, 5],
'min_samples_leaf': [1, 2, 3, 5],
'random_state': [42]
}
gbr_search = GridSearchCV(gbr, param_grid=gbr_params, cv=5, scoring='neg_mean_squared_error', n_jobs=-1)
gbr_search.fit(X_train, y_train)
best_mse = (-1) * gbr_search.best_score_
best_rmse = np.sqrt(best_mse)
print('Best score: {}, Best params: {}'.format(round(best_rmse, 4), gbr_search.best_params_))
RandomForest - 하이퍼 파라미터 튜닝
rf_final = RandomForestRegressor(**rf_search.best_params_)
rf_final.fit(X_train, y_train)
y_pred_rf = rf_final.predict(X_test)
name = rf_final.__class__.__name__
# Test RMSE
mse_rf = mean_squared_error(y_test, y_pred_rf)
print('RMSE of %s: %.4f' % (name, np.sqrt(mse_rf)))
LGBM - 하이퍼 파라미터 튜닝
# LGBM
lgbm_params = {
'num_leaves': [25, 31, 35],
'learning_rate': [0.01, 0.05, 0.1, 0.5],
'n_estimators': [100, 300, 500, 1000],
'max_depth': [3, 7, 11],
'random_state': [42]
}
lgbm_search = GridSearchCV(lgbm, param_grid=lgbm_params, cv=5, scoring='neg_mean_squared_error', n_jobs=-1)
lgbm_search.fit(X_train, y_train)
best_mse = (-1) * lgbm_search.best_score_
best_rmse = np.sqrt(best_mse)
print('Best score: {}, Best params: {}'.format(round(best_rmse, 4), lgbm_search.best_params_))
GBM - 회귀 모델 학습 / 예측 / 평가
gbr_final = GradientBoostingRegressor(**gbr_search.best_params_)
gbr_final.fit(X_train, y_train)
y_pred_gbr = gbr_final.predict(X_test)
name = gbr_final.__class__.__name__
# Test RMSE
mse_gbr = mean_squared_error(y_test, y_pred_gbr)
print('RMSE of %s: %.4f' % (name, np.sqrt(mse_gbr)))
RandomForest - 회귀 모델 학습 / 예측 / 평가
rf_final = RandomForestRegressor(**rf_search.best_params_)
rf_final.fit(X_train, y_train)
y_pred_rf = rf_final.predict(X_test)
name = rf_final.__class__.__name__
# Test RMSE
mse_rf = mean_squared_error(y_test, y_pred_rf)
print('RMSE of %s: %.4f' % (name, np.sqrt(mse_rf)))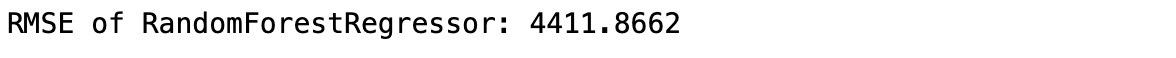
LGBM - 회귀 모델 학습 / 예측 / 평가
lgbm_final = LGBMRegressor(**lgbm_search.best_params_)
lgbm_final.fit(X_train, y_train)
y_pred_lgbm = lgbm_final.predict(X_test)
name = lgbm_final.__class__.__name__
# Test RMSE
mse_lgbm = mean_squared_error(y_test, y_pred_lgbm)
print('RMSE of %s: %.4f' % (name, np.sqrt(mse_lgbm)))
'개발 > 💠 Alchemist' 카테고리의 다른 글
| 💠 AIchemist AIdeaton 기획 💠 (3) | 2023.12.26 |
|---|---|
| 💠 군집화 💠 (0) | 2023.11.28 |
| 💠 회귀 - 캐글 주택 가격: 고급 회귀 기법 💠 (0) | 2023.11.21 |
| 💠 회귀 - 캐글 자전거 대여 수요 예측 실습 💠 (1) | 2023.11.18 |
| 💠 AIchemist 6주차 💠 (0) | 2023.11.08 |