2024. 9. 15. 17:37ㆍ개발/🦉 뀨업
수정 사항 및 고민
💟 1번 수정사항
솔브닥 API로 학생들 정보를 크롤링하니까 솔브닥에 가입하지 않은 학생 정보는 오지 않아서 백준으로 크롤링하기로 함
(대신 상위 40명만)
이에 따라 교내 랭킹 기능은 삭제 -> 상위 40명 안에 본인 이름 없으묜 서운해... + 어차피 백준으로 랭킹 볼 듯
💟 2번 수정사항
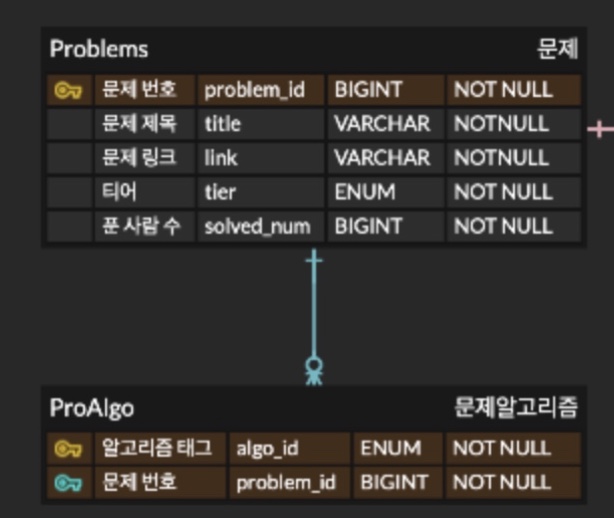
기존 : Problems table과 Algorithms table 다대다 관계라서 중간 테이블(ProAlgo table) 삽입
수정 : Problems table과 ProAlgo table만 일대다 관계로 생성
-> Algorithms table은 어차피 속성이 algo_id 밖에 없으므로 enum으로 관리
💟 3번 수정사항
organization, name, rank가 예약어라 각각 Organizations, group_name, ranking으로 수정
ranking을 Organizations의 PK로 설정
💬 1번 고민 : ProAlgo의 algo_id 인덱스로 설정할까?
💬 2번 고민 : ProAlgo 테이블의 algo_id, problem_id를 복합키이자 기본키로 둘까?
2번 수정사항 : Problems table이랑 ProAlgo table
1차 ERD

2차 ERD

원래는 Problems table이랑 Algorithms table이 다대다 관계이기 때문에
Problems table이랑 Algorithms table 사이에 ProAlgo table(중간 테이블)을 생성했었다
다대다 관계 상황에서는 항상 그래왔기에...
그러다 희원이가 Algorithms table을 삭제하는 건 어떠냐는 제안을 해주었다
고민을 해보니
여태까지 다대다 관계에서 중간 테이블을 끼웠을 때는 상대 테이블에서 가져와야 하는 정보가 많을 때였다
중간 테이블에는 서로의 PK만 넣고 PK를 통해서 상대 테이블의 속성들을 이용했다
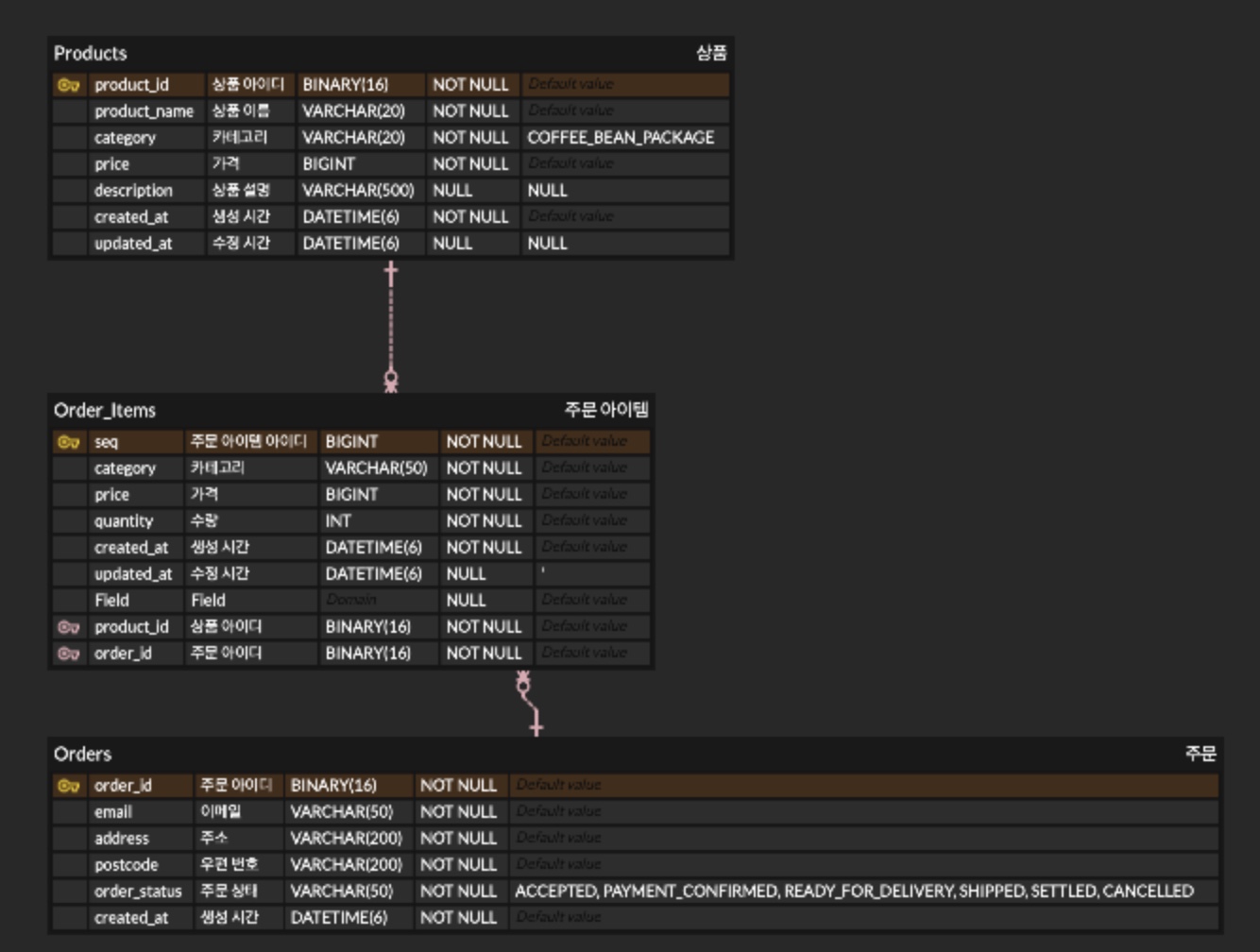
위와 같은 상황처럼 Products table과 Orders table 둘다 가지고 있는 속성이 여러개이며 다대다 관계일 때
Order_Items table을 생성해서 서로의 PK를 넣고 이를 통해 서로의 속성을 사용하는 것이다
하지만 뀨업의 경우에는 사실 Algorithms table에서 가져오는 정보가 알고리즘 태그 하나였다

그렇다면 굳이 복잡하게 중간 테이블을 끼워넣고, PK를 타고 들어가는 식이 아니라
ProAlgo table에 알고리즘 태그를 넣어버리는 게 훨씬 깔끔하고 적절하다
역시 기계적으로 결론만 외워서 하는 개발은 위험하다...
다대다 관계일 때 중간 테이블을 넣는 이유를 명확하게 정의하지 않고 냅다 항상 그래왔으니까..! 하면서 ERD를 설계했다...
반성...
첫번째 고민 사항! ProAlgo의 algo_id 속성을 index로 설정할 것인가...??
결론은 놉...❌❌❌
왜냐...
두가지의 이유가 있다
1. Problems table, ProAlgo table의 빈번한 DELETE 및 INSERT
뀨업은 하루에 한번씩 데이터 크롤링을 하고 크롤링한 데이터를 테이블들에 업데이트한다
다들 알다시피 인덱스는 SELECT에서는 높은 효율을 보이지만, INSERT / UPDATE / DELETE에서는 성능 저하를 일으킨다
따라서 인덱스를 생성해봤자 매일 인덱스를 삭제, 재생성해야 하고 이는 성능과 비용 측면에서 좋지 않다
인덱스 사용할 때 왜 INSERT / DELETE / UPDATE 성능이 저하되는가....
https://minnseong.tistory.com/19
[DB] Index 정리
Index 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스의 검색 속도를 향상하기 위한 자료구조 Index를 통해 검색 속도 향상과 조회 성능을 높일 수 있다. Index를 사용하지 않는 칼럼을 조
minnseong.tistory.com
2. algo_id의 낮은 카디널리티
algo_id는 8가지의 Enum 형태로 구성되어 있다
problems 레코드는 엄청나게 많은데 algo_id는 고작 8가지이기 때문에 매우 낮은 카디널리티를 보인다
데이터베이스는 카디널리티를 확인하고 이렇게 낮은 카디널리티 상황에서는 알아서 인덱스 스캔 말고 풀 스캔 방식을 택한다고 한다
결론은 algo_id로 인덱스 생성해봤자 풀 스캔 방식을 택할 것이기 때문에 무의미하다
https://yurimkoo.github.io/db/2020/03/14/db-index.html
유림's Blog
베짱이가 되고 싶은 개미의 기술 블로그
yurimkoo.github.io
요 블로그 보니까 카디널리티뿐만 아니라 선택도도 너무 높아서 algo_id를 인덱스로 삼는 것은 비효율적일 듯 싶다
두번째 고민 사항! ProAlgo의 algo_id와 problem_id 속성을 복합키이자 기본키로 설정할 것인가...??
요놈도 결론은 놉...❌❌❌
왜냐...
뀨업의 기능에는
1 ) problem의 algo_id 조회(problem_id를 기준으로 algo_id 조회)
2 ) algo_id 기준으로 problem 조회(algo_id를 기준으로 problem_id 조회)
두가지가 있다
이때 복합키는 튜플 형식으로 묶이고 둘의 조합으로 즉, 묶인 상태의 칼럼으로 조회를 수행할 때는 성능이 좋지만
각각의 칼럼으로 조회를 수행할 때는 성능 저하가 발생할 수 있다
(algo_id, problem_id) 복합키 상태일 때 조회하고자 하면
무조건 algo_id -> problem_id 순서로 기준을 바꿔서 조회를 수행한다
즉, 1번 기능(problem_id를 기준으로 algo_id 조회 필요)이 수행될 때도
무조건 algo_id를 기준으로 조회를 먼저 수행한 뒤 problem_id를 기준으로 조회를 수행한다
따라서 복합키 튜플의 두번째 키를 기준으로 조회 작업을 할 때는 풀 스캔 혹은 이중 스캔이 발생하기 때문에 성능상 좋지 않다는 것이다
따라서 problem_id와 algo_id를 복합키로 묶지 않을 것이고
이에 따라 PK가 따로 필요하므로 AUTO_INCREMENT 되는 pro_algo_id를 따로 설정할 생각이다
수정된 3차 ERD

사실 JPA로 복합키 구현하는 거 궁금해서 고민 없이 냅다 구현해봄...
아래는 구현할 때 참고한 블로그
https://velog.io/@qwerty1434/jpa에서-외래키이자-복합키인-값-다루기
jpa에서 외래키이자 복합키인 값 다루기
@EmbeddedId와 @MapsId를 이용한 연관관계 설정
velog.io
뜨아 ERD 구조가 우다다 바뀌어서 코드 수정 많이 해야 할 듯...
파이티이이잉
RDS 언제 연결해보지..... 흐엉엉ㅇ
'개발 > 🦉 뀨업' 카테고리의 다른 글
| 🦉 뀨업 - 이화 백준 사이트 리팩토링 ( 6 ) - CORS가 또... (0) | 2025.03.01 |
|---|---|
| 🦉 뀨업 - 이화 백준 사이트 리팩토링 ( 5 ) - CORS, 쿠키랑 싸우기 (0) | 2025.02.01 |
| 🦉 뀨업 - 이화 백준 사이트 리팩토링 ( 4 ) MyBatis Migration (0) | 2025.01.17 |
| 🦉 뀨업 - 이화 백준 사이트 리팩토링 ( 3 ) (0) | 2025.01.04 |
| 🦉 뀨업 - 이화 백준 사이트 리팩토링 ( 1 ) (0) | 2024.09.01 |